
作者: Yolo,Cipholio Ventures
1、ZK的技术具有隐私和扩容两个最主要的使用场景,当我们讨论隐私的时候,我们利用ZK技术保护链下数据,不被获取;而当我们讨论扩容的时候,我们则是利用ZK节省链上计算空间。举个例子,如果我要确认某个账户有100块钱,传统区块链的方式是让每个节点都确认一遍,而现在我只需要一个节点,在保证数据完整性的前提下,找到最近净流入100块的凭证,即可证明账户有100元,区别就是前者需要大量计算和证明,后者只需要链下证明。
2、ZKVM发展的核心权衡在于是发挥ZK潜力重要,还是发挥目前开发者资源重要。围绕着发挥ZK潜力,意味着CPU寄存器的硬件加速,IR语言和assembly语言的再组织;而围绕着利用开发者资源,则意味着Solidity转化bytecode后,如何将Bytecode所映射的opcode,进行ZK证明的问题。
3、按照模块化区块链的观点,L1解决共识问题,L2解决计算和执行问题,DA层解决数据可得性和完整性的问题。由于Zk类的L2其证明。
4、以assembly 语言独立设计ZK证明的专用型的ZKapp,由于具有较低的可组合性和解耦能力,将在未来的发展过程中面临很大的阻碍。这些方案由于和其他ZK方案不兼容VM,不兼容语言,不兼容,存在较大的调用难度。
5、依赖,时间序列的交易Log,数据安全性和证明的完整性决定了其执行的可靠性。在目前ZK方案大部分闭源的状态下,ZK安全审计有很大的发展前景。
6、由于ZKP依赖链下数据,交由DA链则会失去数据的隐私性。想要兼容数据隐私性和ZK证明节点不作恶,就需要新的解决方案。我们看好未来诸如MPC/FHE等安全计算方案。
7、随着不同Circuit的不断成熟,Zk证明可能也会迎来提效和分工,ZK证明的硬件提速方案,以及专业的ZK矿工也可能应运而生。
8、ZKP经验局限性问题。典型问题包括:约束系统(constraint system)无法有效约束数据,当证明一些复杂交叉的命题时,约束面临不够充分的问题;私有数据泄露,私有数据当做公开数据处理;针对链下数据的攻击,合约层的“metadata-attack”;ZK证明节点的作恶等等。
9、短期来看,ZK方案的安全性存在局限,目前大量的共识还是建立在链下节点的自律上,缺乏一系列必要的工具(测试,证明,等等),来保障链下环境的安全性。
概览
一直以来ZK技术由于其重峦迭嶂的专业术语,使得人们难以对这一主题充分讨论。本文将着重从生态发展角度,来分析ZK技术和其应用场景,描述目前ZK相关的竞争格局,并为未来发展的方向做一些畅想。本文着重讨论:
- 当我们在讨论ZK技术的时候我们在讨论什么?(知识铺垫,机构投资者可以从第二部分开始读。)
- 从技术发展角度看待gzkvm(generalized zk vm)的发展规律和结构?
- 目前主要ZKvm技术方案的比较?
- 分析和展望
一、虚拟机ABC--从日常计算机说起
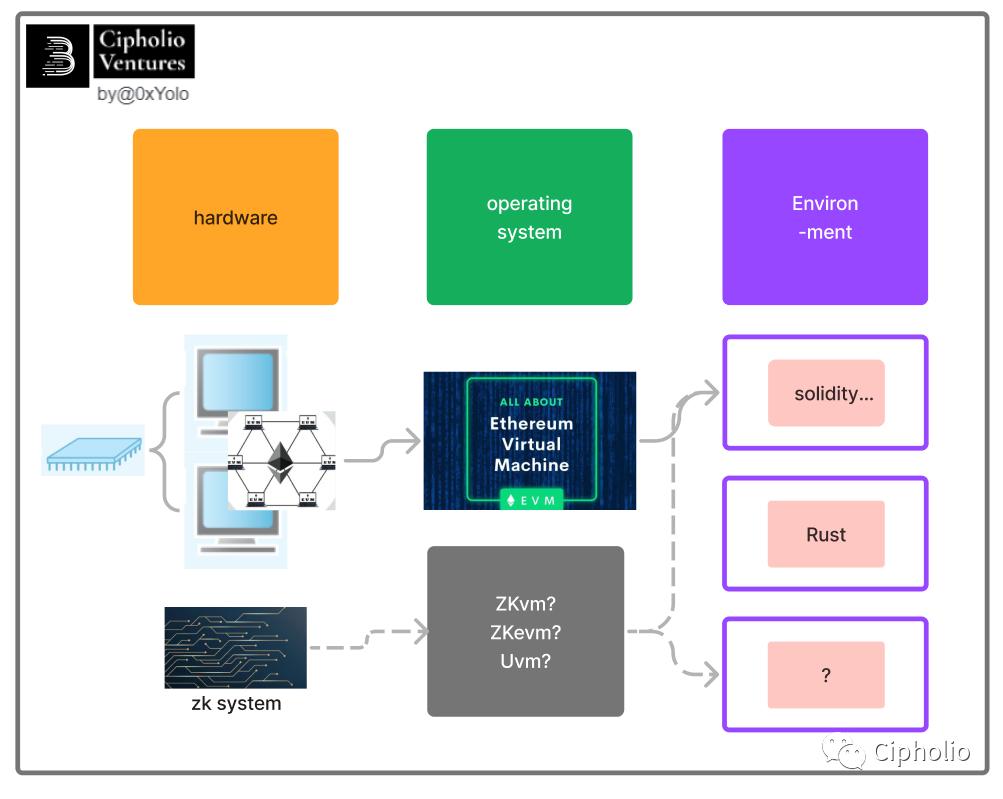
在介绍ZKEVM相关的知识以前,我想先从我们日常的计算机的结构讲起。我们都知道计算机分为软件和硬件两部分,为了让软件顺利的在硬件上运行,我们需要为软件匹配适宜的运行环境。从结构来看,运行环境由【硬件+操作系统】两部分组成。
其中黄色部分为硬件,绿色部分为操作系统。这里可能有同学会提出疑问:为什么运行环境不等价于操作系统,这主要是因为操作系统难以兼容所有的硬件,只有操作系统和硬件的匹配才能为软件提供服务。这个问题,我们再后面ZKVM的发展路线钟,还会提到。
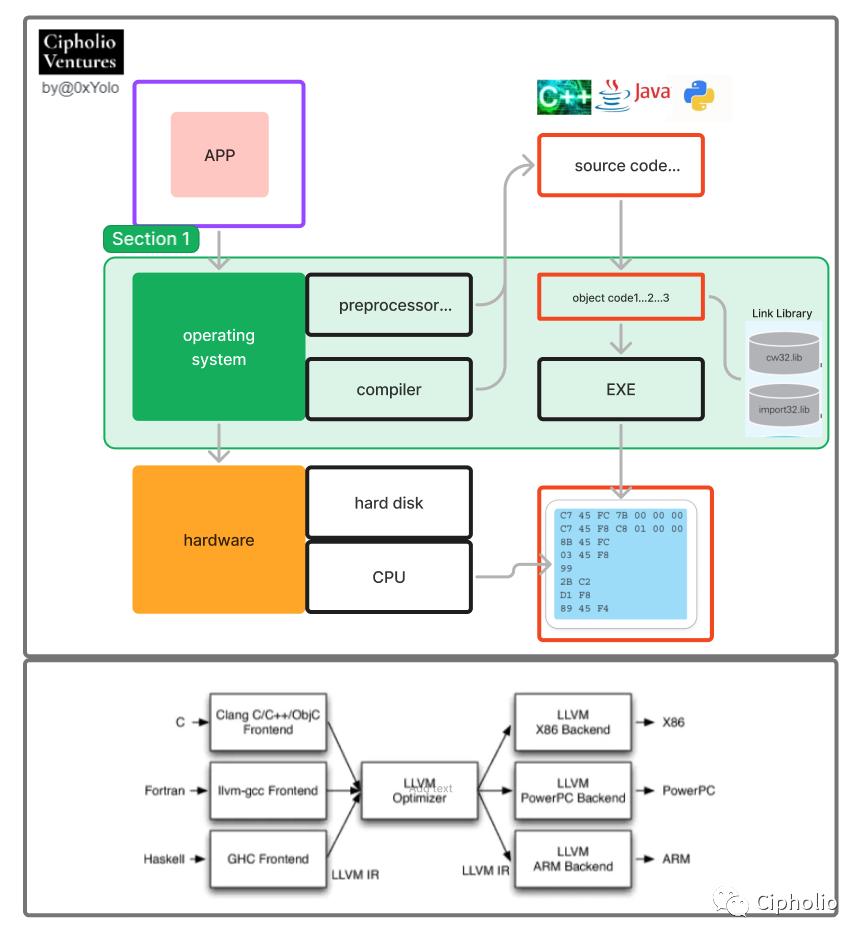
有了运行环境,我们还需要具体的软件(程序/app)才可以实现具体需求。那么程序是怎样跑起来的呢?
从图上我们可以看到,软件经操作系统交由硬件层来进行计算的整个流程,在过程中程序语言经过了三个阶段的变化,高级语言用来写程序完成实际需求,汇编语言用来和计算机沟通,底层本地代码(16进制数)由计算机具体执行。具体来看,程序员完成APP的代码后,经由转译器翻译成obj(目标语言),这些离散的目标语言,将会通过操作系统中的Linker得以链接,两者输出可执行的exe文件存储在硬盘中。
当运行的时候,exe文件会将数据放入内存,经由CPU将Obj转化为本地代码(字节码)进行计算操作,实现app的I/O。这一过程中存在非常多的选择,多样的语言,多样的操作系统,多样的硬件,从商业角度面临了非常多的Tradeoff,而这些选择最后便体现在编译器内核LLVM(low level virtual machine)的改进中。
下图我们可以看到,硬件(黄色)和操作系统之间有多种对应关系和限制条件:
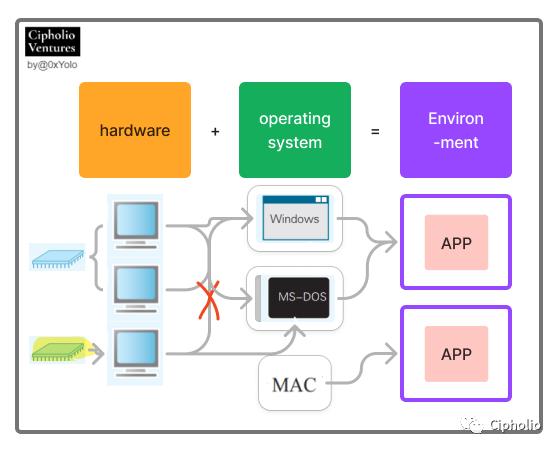
同一类型的硬件可以安装多种操作系统,不同硬件需要匹配不同类型的操作系统。例如, 同样的 AT 兼容机 A 中, 既可以安装 Windows, 也可以安装 LinuxB 等操作系统。又如,X86芯片的硬件,需要x86版本的windows来匹配。这主要是由于操作系统底层汇编语言需要与芯片匹配。
App的成功运行需要与CPU匹配,也需要与操作系统匹配。例如:1,为了保证 Office 2017 的正常运行, 需要具备 x86C 的 CPU;2,有些APP只能在window XP上运行,在2000上则运行不了。
CPU 只能解释其自身固有的机器语言。不同的 CPU 能解释的机器语言的种类也是不同的。也就是说,用不同高级语言编写的APP,如果不能通过【操作系统】编译成CPU可以运算的语言,CPU也是无法执行的。
二、Zk VM是什么?
通常我们在讨论ZK的时候,通常是在三个语境当中:
- 使用ZK作为Scaling方案RollupL2。
- 使用zkp进行证明的应用,dydx,Zklink等等。
- zkproof作为一种密码算法。
用什么语言,在什么环境下,用什么硬件执行?这是广义VM所要解决的问题。
前面我们刚刚介绍了传统操作系统(也是一种VM),再来看ZKVM的时候,我们可以发现,ZKVM也完成了类似的职能,完成了硬件层(原生链+ZK证明系统)和高级语言(solidity或者原生ZK语言)的沟通。其核心是数据证明与状态更新,当系统接收到两类input,原始数据(状态和指令)和证明(对于状态和指令的相关证明),比对计算后,输出指令(更新状态)和ZKP(证明),提交L1进行共识广播。

具体来看ZK证明经过几个部分(by JP Aumasson, Taurus):
1. 本地的计算;
2. Circuit的定义。比如确认你钱包有没有钱,确认信息是不是完整,确认签名是否正确;
3. 算术化证明:运用数学方法证明计算是可执行的。
4. 将算数证明结果和实际结果比对
5. 将结果递交上链
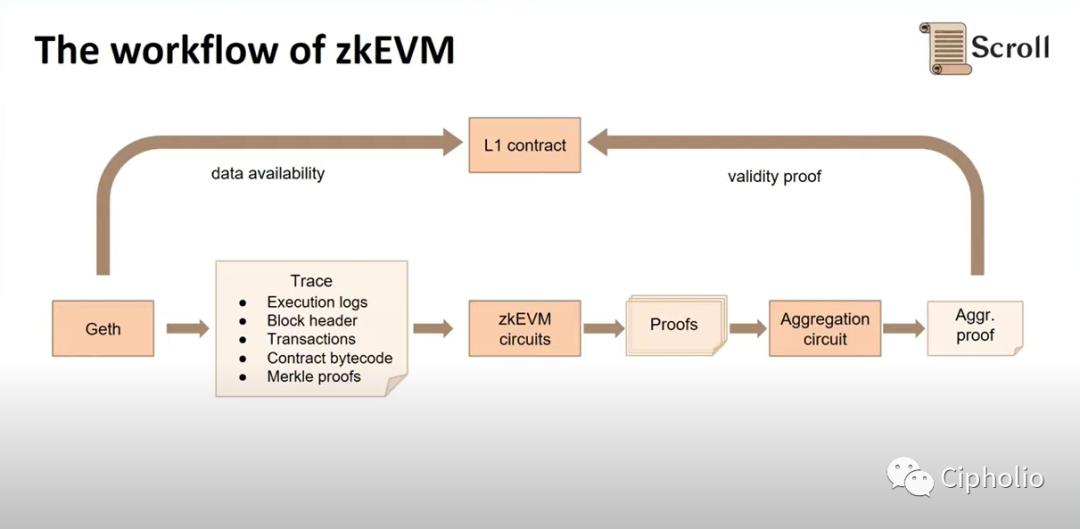
以Scroll的方案为例,我们看到从Geth出发,系统完成了本地的计算,将交易Trace(交易的历史log)拆解转化成Circuits算子,然后使用算数方法(例如多项式拆解,密码学)得出ZK证明。然后比对数据和证明,如果无误即可广播上链。这当中涉及许多关键技术,比如如何设定Circuits,有哪几类Circuits?如何对Circuits进行拆解? 整个确认方法,可以想象一张巨大的表,每一个变量都有其参数,在已知历史数据的背景下,求特定结果的必然性。
举个例子,如果我要确认某个账户有100块钱,传统区块链的方式是让每个节点都确认一遍,而现在我只需要一个节点,在保证数据完整性的前提下,再加上最近净流入100块的证明,然后进行确认(案例中的情形比较简单,看一眼便知,实际情况中是需要数学运算的。)完成后,即可证明账户有100元,区别就是前者需要每一个节点的计算,后者只需要单一节点计算和zk证明。在这个例子中,确认的是“如何在链下证明账户有充足余额”,证明需要的约束是“当最近历史时间轴内账户净流入大于100(实质基于Merkle Root的证明),然后将节点计算结果与ZKP比对,从而决定状态是否正确。
ZK语言的公约数

根据MidenVM 的总结,目前市场上主要的Zkapp所采用的的工具都是以WASM和RISC V为主的汇编语言,一些工具包能让应用很快打上“ZK”的概念或者标签。但稍微拆解一下结构,我们会发现传统智能合约由L1来保证安全性,全网广播形成共识的安全性已经经过历史检验了,而利用链下ZKP证明,则存在ZKP证明节点是否作恶的问题。
先不论Devs是否能够合理设立约束(Contraint)的能力问题,如何防范ZKP证明节点的作恶意愿问题,无疑是更为重要的。
举例来看,一些ZK dex更像是在Cex和Dex之间寻找一个平衡点,相较于Cex而言,用户可以将资金保管在自己的L1账户;而相对Dex而言,又能有更优的效率表现。但在实践中,大量的项目都存在链下证明的安全隐患。此外,由于从APP层到IR层,都是由zkAPP团队独立开发,家家户户有着自己的编程习惯和轮子库,这也导致团队与团队之间难以形成可组合性,也不利于加速市场分工和硬件设备的加速。
因此,市场破解寻找一个在密码学和高级语言之间找到一层公约数。来为各类应用提供一个通用的框架,而ZK-VM则是适配整套系统,承上启下的重要部分。
在执行模式方面,EVM与JVM非常相似。两者都是执行字节码的堆栈机。EVM增加了一个存储的概念,它的字节码指令更适合于合同开发。
图中我们以ETH举例,传统ETH由三部分构成,ETH网络(节点+共识机制),EVM,Dapp开发生态。这里我们可以很清晰的感受到ZK承上启下的作用:
1. 站在ZK电路硬件层的角度:
EVM可能无法全部兼容。由于EVM有一些变长的指令,比如CALL,DATACOPY,EXP,CREATE等等,这些对ZK电路不友好。
2. 站在开发者角度:
能否不需要重新学习语言(Solidity仍然兼容),保留EVM的API特性。在这种情况下,整个生态就可能失去对一些ZK算法的支持。
除此以外,ZKVM还需要考量很多技术兼容,比如:
1. 寄存器的兼容。Machine Type. 传统EVM是一个Stack-based的State machine,因此大量的计算式串联的,不可并行的,这确保了整个计算机的原子性。这一架构对于ZK是非常不利的,如果要发挥ZK算法的全部效率,则需要做一个Register-Based,也就是以CPU-寄存器为核心架构来设计VM。
2. 语言上的兼容。Function Calls. VM系统将底层特性封装成API,如何让API支持动态调用,支持像Python一样的高级语言。
3. 计算机底层的兼容。Native Field. 不同的CPU有不同的位数,在不同算法上的表现不同。需要为ZK专用计算机做谋划。
4. 传统公链结构的兼容: Sequencer/Roller/Miner.
三、ZKVM的架构
主流技术方案
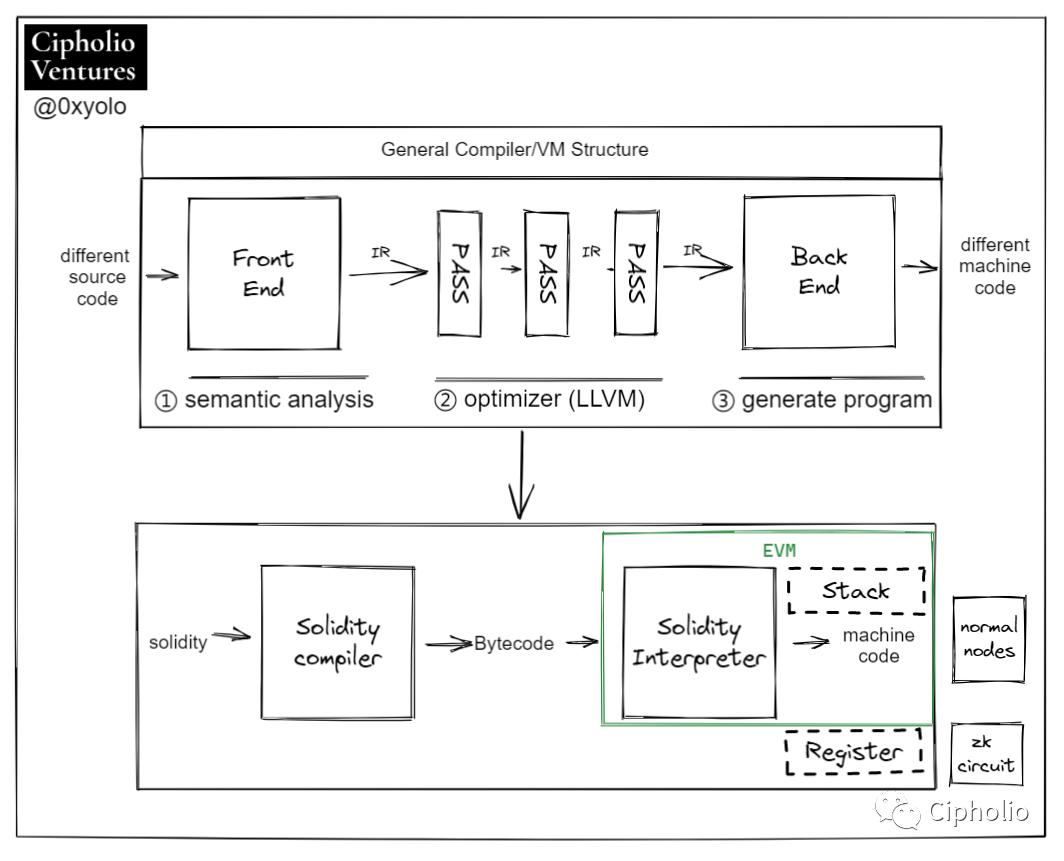
用什么语言,在什么环境下,用什么硬件执行?这是广义VM所要解决的问题。
VM当中最为重要的内核便是LLVM(low-level-virtual-machine),他可以看作是编译器最重要的内核。图中是原始EVM的运作方案,智能合约通过LLVM IR 的中间代码进行转化,转化成Bytecode。这些Bytecode会存储在区块链上,当智能合约被调用的时候,便会将Bytecode转化成对应的Opcode,再由EVM和节点硬件来执行。
结合上ZK,各个不同的解决方案是怎样实现的呢?
Starkware
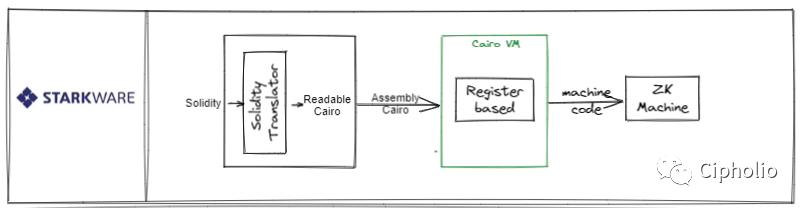
Starkware由于在整个ZK领域起步较早,技术积累较为充分,拥有一定的技术领先。他是代表性的ZK中心主义的技术架构,围绕ZK构建了Cairo VM和Cairo的语言。但由于他是闭源状态,一些技术细节并不清晰。其缺点在于,Cairo的学习成本。虽然官方也开发了Solidity转换Cairo的一些框架,但由于其底层核心均建立于CairoVM上,意味着有相当多Solidity-EVM兼容的特征会损失。
Zksync
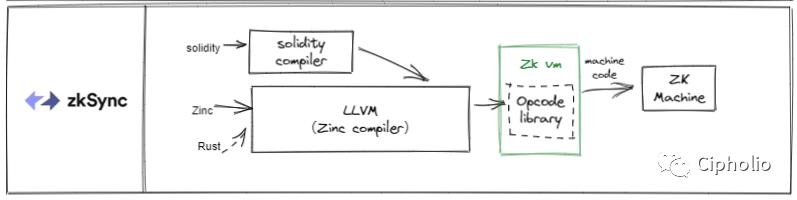
ZKsync 的框架兼容了EVM和ZK两方面的特点,将Solidity和其自主开发的电路语言Zinc做了一个融合,在编译器内部将两者在IR层面上做了统一。其优点在于编译器内核的LLVM可以兼容多种语言。Zksync也是闭源框架。
Hermez by Polygon
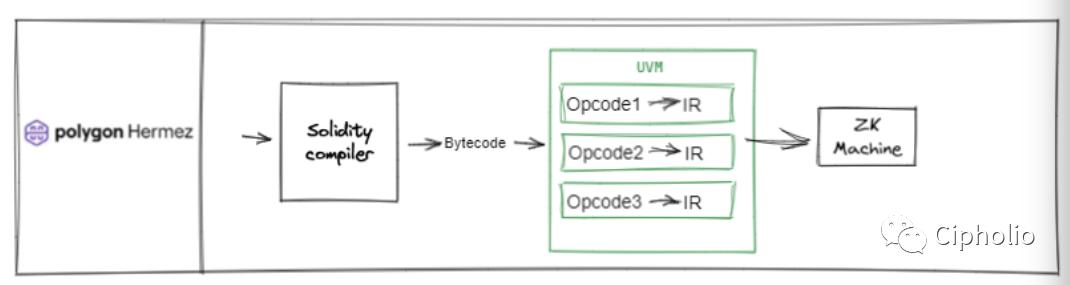
Scroll
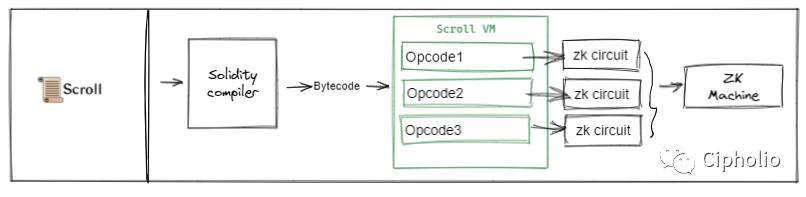
HermZ和Scroll两个技术方案更侧重以太坊生态,他们在Bytecode上和ETH生态做了融合。由于EVM天然支持bytecode和其对应的opcode,这两者和ETH生态有着更高的融合性。Solidity在这两个Zkvm上能充分的调用EVM的API,最大保留了EVM的架构优点。两个方案有所差异的是,Hermz会将opcode在内部进行统一,然后再进行证明;而Scroll则会将Opcode拆解circuit进行证明,再进行整合。
为什么要选择兼容EVM?因为EVM当中有一些架构经过检验,安全性比较好,兼容性也比较好。举例来说Geth模型和RPC架构,这些API已经被EVM较好的封装,也经过历史检验。
总结来看,
- Starkware最底层从WASM和机器码层面进行统一,ZKsync最浅在IR层面进行统一,Hermz和Scroll居中在Bytecode上进行统一;
- Starkware是技术转型最彻底的,但也是用户学习门槛最高的;而Zksync相对比较均衡,保留一部分solidity特性,发挥局部ZK性能;
- Hermz和Scroll相对最易应用和拆解,全面集成Bytecode,整合EVM,尤其是Scroll,开放ZK证明,也给了硬件加速更大的空间。
- 相对来说,无论是技术驱动还是生态整合驱动,都在未来有各自的发展空间,“贸工技”还是“技工贸” 都有机会找到自己的场景,发挥更大价值。
如果我们对照回顾Windows历史,在强有力的操作系统出现以前,不同的开发者需要对不同的硬件,掌握不同的开发工具。不掌握汇编,不理解计算机底层的开发者在开发过程中会遇到非常多的挫折。而操作系统在硬件当中寻找最大的公约数,将CPU以外的I/O系统都封装成统一的接口,这些技术积累,使得软件开发的门槛大大降低了,也使得大部分程序员只需要理解高级语言即可,即使不具备汇编和底层代码知识仍然可以写出漂亮的App。
对照看到ZKVM的发展,我们可以看到一些端倪,如果说现在的ZKapp需要传统程序员+汇编+密码学知识储备才能开发,未来随着ZKVM的成熟,越来越多的底层技术封装进高级语言当中,开发门槛渐次降低,生态繁荣是可以想见的。
对于Founder而言,有两个注意点:
1. ZK技术将链上共识转为链下证明,目前证明技术相对成熟,但是拆解证明,数据存储的安全隐患仍然不少,相关审计机构,测试工具都存在空白缺位。
2. ZK技术的使用场景尚待发掘。通用型ZKVM紧锣密鼓开发,ZK对应高级语言也有待技术人员的学习,从技术成熟到解决问题还有一段时间。想要用ZK解决问题,founder需要回答:如果是个细分场景,是否需要自己用WASM去搭建,一旦ZKVM成熟,自己的技术积累是否还有先发优势?是否支持其他ZKapp调用?
展望与结论
ZK的技术具有隐私和扩容两个最主要的使用场景,当我们讨论隐私的时候,我们实际上是在保护链下数据,不被获取;而当我们讨论扩容的时候,我们是利用ZK节省链上计算空间。
- ZKVM发展的核心权衡技术与devs。围绕着发挥ZK潜力,意味着CPU寄存器的硬件加速,IR语言和assembly语言的再组织;而围绕着利用开发者资源,则意味着Solidity转化bytecode后,如何将Bytecode所映射的opcode,进行ZK证明的问题。
- 以assembly 语言独立设计ZK证明的专用型的ZKapp,由于具有较低的可组合性和解耦能力,将在未来的发展过程中面临很大的阻碍。这些方案由于和其他ZK方案不兼容VM,不兼容语言,不兼容证明,存在较大的调用难度。
- 按照模块化区块链的观点,L1解决共识问题,L2解决计算和执行问题,DA层解决数据可得性和完整性的问题。由于Zk类,数据安全性和证明的完整性决定了其执行的可靠性。这里有一对矛盾,如果我们不信任链下节点,希望将数据交由DA独立存储,那么对DA链就提出安全的要求,;如果存在本地,保证数据不被篡改,就需要证明节点本身不去作恶。这些都提升了对MPC/FHE解决方案的需求。
- 在目前ZK方案大部分闭源的状态下,目前大量的共识还是建立在链下节点的自律上,缺乏一系列必要的工具(测试,证明,等等),来保障链下环境的安全性。未来contraint设计和代数证明将成为两个最主要的审计环节。
- ZK生态主要的风险。典型问题包括:约束系统(constraint system)不充分。当证明一些复杂交叉的命题时,约束面临不够充分的问题;私有数据泄露。私有数据当做公开数据处理;针对链下数据的攻击,合约层的“metadata-attack”;ZK证明节点的作恶等等。
- 随着不同Circuit的不断成熟,Sequencer/Roller/Miner 也会迎来提效和分工,我们期待ZK证明的硬件加速机会。




